Перевод шестого поста цепочки Бирнса. (Оригинал)
- В чём проблема и почему работать над ней сейчас?
- «Обучение с чистого листа» в мозгу
- Две Подсистемы: Обучающаяся и Направляющая
- «Краткосрочный предсказатель»
- «Долгосрочный предсказатель»
- Большая картина мотивации, принятия решений, и RL
- От закодированных стремлений к предусмотрительным планам: рабочий пример
- Отходим от нейробиологии, 1 из 2: Про разработку СИИ
- Отходим от нейробиологии, 2 из 2: Про мотивацию СИИ
- Задача согласования
- Согласованность ≠ безопасность (но они близки!)
- Два пути вперёд: «Контролируемый СИИ» и «СИИ с социальными инстинктами»
- Укоренение символов и человеческие социальные инстинкты
- Контролируемый СИИ
- Заключение: Открытые задачи и как помочь
***
6.1 Краткое содержание / Оглавление
Пока что в этой цепочке Пост №1 задал некоторые определения и мотивации (что такое «безопасность подобного-мозгу ИИ», и с чего нам беспокоиться?), Посты №2 и №3 представили разделение мозга на Обучающуюся Подсистему (конечный мозг и мозжечок), которая использует алгоритмы «обучения с чистого листа», и Направляющую Подсистему (гипоталамус и мозговой ствол), которая в основном генетически-прошита и выполняет специфичные для вида инстинкты и реакции.
В Посте №4 я описал «краткосрочные предсказатели» – схемы, которые в результате обучения с учителем начинают предсказывать сигналы до их появления, но, наверное, лишь за долю секунды. В Посте №5 я затем предположил, что если сформировать замкнутую петлю с участием и краткосрочных предсказателей в Обучающейся Подсистеме, и соответствующих им прошитых схем в Направляющей Подсистеме, то можно получить «долгосрочный предсказатель». Я заметил, что схема «долгосрочного предсказателя» сильно схожа с обучением методом Временных Разниц.
Теперь, в этом посте, мы добавим последние ингредиенты – грубо говоря, «субъекта» из обучения с подкреплением «субъект-критик» (RL) – чтобы у нас получилась полная большая картина мотивации и принятия решений в человеческом мозге. (Я говорю «человеческий мозг» для конкретики, но в любом другом млекопитающем, и, в меньшей степени, в любом другом позвоночном, всё было бы похоже.)
Причина, почему меня волнует мотивация и принятие решений, в том, что, если мы однажды создадим подобные-мозгу СИИ (как в Посте №1), мы захотим обеспечить, чтобы у них были некоторые мотивации (например, быть полезным) и не было некоторых других (например, выйти из-под человеческого контроля и распространить свои копии по Интернету). Куда больше на эту тему в следующих постах.
Тизер предстоящих постов: Следующий пост (№7) пройдётся по конкретному примеру модели из этого поста, и мы сможем пронаблюдать, как встроенное стремление приводит к сначала формированию явной цели, а потом принятию и исполнению плана для её достижения. Потом, начиная с Поста №8, мы сменим контекст, и с этого момента вы можете ожидать значительно меньше обсуждения нейробиологии и значительно больше обсуждения безопасности СИИ (за исключением ещё одного поста про нейробиологию ближе к концу).
Всё в этом посте, если не сказано обратное, это «то, в чём я убеждён прямо сейчас», а не нейробиологический консенсус. (Лайфхак: нейробиологического консенсуса никогда нет.) Я буду принимать минимальные усилия для связи своих гипотез с другими из литературы, но буду рад поболтать об этом в комментариях или по email.
Содержание:
- В Разделе 6.2 я представлю большую картину мотивации и принятия решений в человеческом мозге и пройдусь по тому, как это работает. Остаток поста будет описывать различные части этой картины более детально. Если вы торопитесь, я предлагаю дочитать до конца Раздела 6.2 и закончить.
- В Разделе 6.3 я поговорю о так называемом «Генераторе Мыслей», состоящем (как мне кажется) из дорсолатеральной префронтальной коры, сенсорной коры и других областей. (Для читателей из области машинного обучения, знакомых с «основанном на модели обучением с подкреплением субъект-критик», Генератор Мыслей более-менее соответствует комбинации «субъекта» и «модели».) Я поговорю о вводах и выводах этого модуля и кратко обрисую, как его алгоритм связан с нейроанатомией.
- В Разделе 6.4 я поговорю о том, как в этой картине работают ценности и вознаграждения, включая сигнал вознаграждения, руководящий обучением и принятием решений в Генераторе Мыслей.
- В Разделе 6.5 я немного больше углублюсь в детали того, как и почему думание и принятие решений должны вовлекать не только одновременные сравнения (например, механизм параллельной генерации разных вариантов и выбора наиболее многообещающего), но и последовательные сравнения (например, думать о чём-то, затем думать о чём-то другом, и сравнить эти две мысли). К примеру, вы можете подумать: «Хмм, я думаю, что я пойду в спортзал. Но, на самом деле, что если я вместо этого пойду в кафе?»
- В Разделе 6.6 я прокомментирую частое заблуждение о том, что Обучающаяся Подсистема – место обитания эгосинтонических интернализированных «глубоких желаний», а Направляющая Подсистема – эгодистонических, экстернализированных «первобытных побуждений». Я буду в целом возражать представлению о том, что две подсистемы – два противостоящих агента; более хорошая ментальная модель – что это две связанных шестерни в одном механизме.
6.2 Большая картина
Да, это буквально большая картинка, если вы только не читаете это с телефона. Вы уже видели её часть в предыдущем посте (Раздел 5.4), но сейчас тут больше всего.

Тут много, но не беспокойтесь. Мы пройдёмся по каждому кусочку отдельно.
6.2.1 Связь с «двумя подсистемами»
Вот как эта диаграмма укладывается в мою модель «двух подсистем», описанную в Посте №3:

Тоже, что и выше, но две подсистемы подсвечены разными цветами.
6.2.2 Быстрый обзор
До погружения в детали дальше в посте, просто пройдёмся по диаграмме:
1. Генератор Мыслей генерирует мысль: Генератор Мыслей выбирает мысль из высокоразмерного пространства всех мыслей, которые возможно подумать в данный момент. Заметим, что это пространство возможностей, хоть и огромное, ограничено текущим сенсорным вводом, прошлым сенсорным вводом и всем остальным в выученной модели мира. К примеру, если вы сидите за письменным столом в Бостоне, в общем случае для вас невозможно подумать, что вы занимаетесь скуба-дайвингом у берега Мадагаскара. Но вы можете составлять план или насвистывать мелодию, или погрузиться в воспоминание, или рефлексировать о смысле жизни, и т.д.
2. Оценщики Мыслей сводят мысль к «оценочной таблице»: Оценщики Мыслей – набор, возможно, сотен тысяч схем «краткосрочных предсказателей» (Пост №4), который я более подробно описывал в предыдущем посте (№5). Каждый предсказатель обучен предсказывать свой сигнал из Направляющей Подсистемы. С точки зрения Оценщика Мыслей, всё в Генераторе Мыслей (не только выводы, но и скрытые переменные) – это контекст – информация, которую можно использовать для создания лучших предсказаний. Так что, если я думаю мысль «я прямо сейчас съем конфету», то Оценщик Мыслей может предсказать «высокую вероятность ощутить вкус чего-то сладкого очень скоро» исключительно на основании мысли – у него нет необходимости полагаться на внешнее поведение или сенсорные вводы, хоть это тоже может быть важным контекстом.
3. «Оценочная таблица» решает задачу построения интерфейса между обучающейся с чистого листа моделью мира и генетически закодированными схемами: Напомню, текущая мысль и ситуация – это невероятно сложные объекты в высокоразмерном выученном с чистого листа пространстве «всех возможных мыслей, которые можно подумать». Но нам нужно, чтобы относительно простые генетически закодированные схемы Направляющей Подсистемы анализировали мысль и выдавали суждение о её высокой или низкой ценности (см. Раздел 6.4 ниже) и о том, требует ли она выброса кортизола, гусиной кожи или расширения зрачков, и т.д. «Оценочная таблица» решает эту проблему! Она сводит возможные мысли / убеждения /планы и т.д. к генетически стандартизированной форме, которую уже можно напрямую передать генетически закодированным схемам.
4. Направляющая Подсистема исполняет некий генетически закодированный алгоритм: Его ввод – это (1) оценочная таблица с предыдущего шага, и (2) прочие источники информации – боль, метаболический статус, и т.д., поступающие из её собственной системы сенсорной обработки в мозговом стволе (см. Пост №3, Раздел 3.2.1). Её вывод включает выбросы гормонов, моторные команды, и т.д., а также посылание управляющих сигналов «эмпирической истины», показанных на диаграмме.[1]
5.Генератор Мыслей оставляет или отбрасывает мысли, основываясь на том, нравятся ли они Направляющей Подсистеме: Более конкретно, есть сигнал эмпирической истины (он же вознаграждение, да, я знаю, что это не звучит синонимично, см. Пост №5, Раздел 5.3.1). Когда его значение велико и положительно, текущая мысль «усиливается», задерживается, и может начать контролировать поведение и вызывать последующие мысли, а когда велико и отрицательно, текущая мысль немедленно отбрасывается, и Генератор Мыслей призывает следующую.
6. И Генератор Мыслей, и Оценщик Мыслей «обучаются с чистого листа» по ходу жизни, благодаря, в частности, управляющим сигналам Направляющей Подсистемы. Конкретнее, Оценщики Мыслей обучаются всё лучшему и лучшему предсказыванию сигнала «эмпирической истины задним числом» (это форма обучения с учителем – см. Пост №4), а Генератор Мыслей в большей степени обучается генерировать высокоценные мысли. (Процесс обучения с чистого листа Генератора Мыслей также включает и предсказательное обучение сенсорных вводов – Пост №4, Раздел 4.7.)
6.3 «Генератор Мыслей»
6.3.1 Общий обзор
Вернёмся к большой диаграмме выше. Слева-сверху находится Генератор Мыслей. В терминах основанного на модели обучения с подкреплением «субъект-критик», Генератор Мыслей грубо соответствует комбинации «субъект» + «модель», но не «критику». («Критик» обсуждался в предыдущем посте, а больше про него – ниже.)
На нашем несколько упрощённом уровне анализа, мы можем думать о «мыслях», генерируемых Генератором Мыслей как о комбинации ограничений (из предсказательного обучения сенсорных вводов) и выборов (управляемых обучением с подкреплением). Подробнее:
- Ограничения Генератора Мыслей происходят из информации из сенсорного ввода и предсказательного обучения сенсорному вводу (Пост №4, Раздел 4.7). К примеру, я не могу подумать мысль «На моём столе кот, и я прямо сейчас на него смотрю.» Кота, к сожалению, нет, и я не могу просто пожелать увидеть что-то, чего очевидно нет. Я могу представить, как я его вижу, но это не та же мысль.
- Но с учётом этих ограничений есть более чем одна возможная мысль, которую мой мозг может подумать в каждый конкретный момент. Он может обращаться к памяти, раздумывать о смысле жизни, выдать команду встать, и т.д. Я утверждаю, что эти «выборы» принимаются системой обучения с подкреплением (RL). Эта RL-система – одна из главных тем этого поста.
6.3.2 Ввод Генератора Мыслей
Генератор Мыслей принимает в качестве ввода, в том числе сенсорные данные и изменяющие гиперпараметры нейромодуляторы. Но в этом посте для нас наибольший интерес представляет сигнал эмпирической истины, он же вознаграждение. Я более детально поговорю о нём позже, но мы можем считать, что это оценка того, хороша или плоха мысль, в смысле, «стоит ли её удержать и развивать или же она заслуживает того, чтобы её выбросили и сгенерировали следующую». Этот сигнал важен и для того, чтобы научиться думать мысли получше, и для думания хороших мыслей прямо сейчас:

6.3.3 Вывод Генератора Мыслей
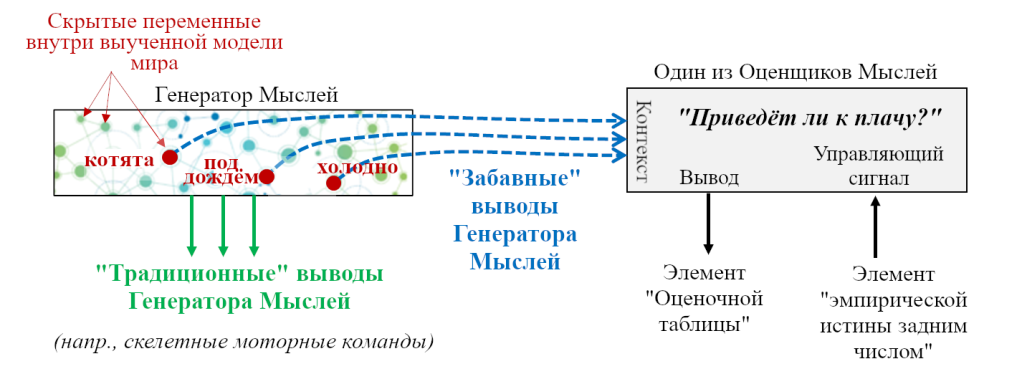
В тоже время множество сигналов выходят из Генератора Мыслей. Некоторые – то, о чём мы интуитивно думаем как о «выводе» – например, скелетные моторные команды. Другие сигналы вывода, ну, это несколько забавно…
Напомню идею «контекста» из Раздела 4.3 Поста №4: Оценщики Мыслей – это краткосрочные предсказатели, а краткосрочный предсказатель в принципе может взять любой сигнал в мозгу и применить его для улучшения своей способности предсказывать свой целевой сигнал. Так что если Генератор Мыслей имеет модель мира, то где-то в этой модели мира есть конфигурация активаций скрытых переменных, кодирующая концепт «маленькие котята, дрожащие под холодным дождём». Мы не стали бы думать об этом как о «сигналах вывода» – я только что сказал, что это скрытые переменные! Но, так уж получается, что Оценщик Мыслей «это приведёт к плачу» применяет копию этих скрытых переменных как контекстный сигнал, и постепенно обучается на опыте, что этот конкретный сигнал сильно предсказывает слёзы.
То есть, сейчас, у взрослого меня эти нейроны «маленьких котят под холодным дождём» в моём Генераторе Мыслей живут двойной жизнью:
- Они являются скрытыми переменными в моей модели мира – т.е. они и их сеть связей помогают мне распознать картинку маленьких котят под дождём, если я такую вижу, и рассуждать о том, что с ними произойдёт, и т.д.
- Активация этих нейронов, например, с помощью воображения – это способ вызвать слёзы по команде.
6.3.4 Обрисовка нейроанатомии Генератора Мыслей
ПРИМЕЧАНИЕ АВТОРА: Изначально в этом разделе было обсуждение петель «кора-базальные ганглии-таламус-кора», но это всё было очень спекулятивно и оказалось несколькими разными способами ошибочным. Это в любом случае не было особо важно для цепочки в целом, так что я это просто удалил. Я как-нибудь напишу исправленную версию отдельным постом. Извините!
Обновлённая дофаминовая диаграмма из предыдущего поста:

В Генераторе Мыслей есть ещё много деталей реализации, которые я тут не обсуждаю, включая детали диаграммы «петли» выше, так же, как и отношения между разными регионами коры. Однако, этого небольшого раздела более-менее достаточно для следующих постов по безопасности СИИ. Запутанные подробности Генератора Мыслей, так же, как и в чём угодно другом в Обучающейся Подсистеме, в основном полезны для создания СИИ.
6.4 Ценности и вознаграждения
6.4.1 Кора прикидывает «ценность», но Направляющая Подсистема может выбрать перехватить
На диаграмме есть две «ценности» (выглядит, будто три, но две красных – одно и то же):

Обведённый синим сигнал – это прикидка ценности из соответствующего Оценщика Мыслей в коре. Обведённый красным сигнал (ещё раз, это один и тот же сигнал, нарисованный дважды) – «эмпирическая истина» о том, какой должна была быть прикидка ценности. (Напомню, что «эмпирическая ценность» – синоним «вознаграждения»; да, знаю, звучит неправильно, см. предыдущий пост (Раздел 5.3.1) за подробностями.)
Так же, как и у других «долгосрочных предсказателей», которые обсуждались в предыдущем посте, Направляющая Подсистема может выбирать между режимом «довериться предсказателю» и режимом «перехвата». В первом случае, она задаёт красный сигнал эквивалентный синему, как будто говорит: «ОК, Оценщик Мыслей, конечно, я поверю тебе на слово». Во втором случае, она игнорирует предложение Оценщика Мыслей, а её собственные встроенные схемы выдают некую другую ценность.[2]
По каким причинам Направляющая Подсистема перехватывает прикидку ценности Оценщика Мыслей? Два фактора:
- Во-первых, Направляющая Подсистема может действовать на основе информации от других (не-ценностных) Оценщиков Мыслей. К примеру, в Эксперименте с Солью Мёртвого Моря (см. предыдущий пост, Раздел 5.5.5), прикидка ценности была «сейчас произойдёт что-то плохое», но в то же время Направляющая Подсистема получила предсказание «я сейчас почувствую вкус соли» в контексте состояния недостатка соли. Так что Направляющая Подсистема как бы сказала себе: «То, что происходит сейчас, очень перспективно; Оценщик не знает, что несёт!»
- Во-вторых, Направляющая Подсистема могла действовать на основе своих собственных источников информации, независимых от Обучающейся Подсистемы. В частности, Направляющая Подсистема обладает собственной системой обработки сенсорной информации (см. Пост №3, Раздел 3.2.1), которая может ощущать биологически-важные намёки вроде боли, голода, вкуса, вида ползущей змеи, запаха потенциального партнёра, и так далее. Всё это и более того может быть возможными основаниями для перехвата сигнала у Оценщика Мыслей, т.е. установке значения обведённого красным сигнала, отличного от обведённого синим.
Интересно (и в отличии от RL «по учебнику»), что в этой большой картине обведённый синим сигнал не обладает в алгоритме специальной ролью, в сравнении с другими Оценщиками Мыслей. Это лишь один из многих вводов прошитого алгоритма Направляющей Подсистемы, решающего, каким сделать обведённый красным сигнал. Обведённый синим сигнал может на практике оказаться особенно важным, более весомым, чем остальные, но вообще они все в одной куче. На самом деле, мои давние читатели вспомнят, что в прошлом году я писал посты, опускавшие обведённый синим сигнал ценности в списке Оценщиков Мыслей! Сейчас я считаю, что это ошибка, но я оставлю примерно такое же отношение.
6.5 Решения вовлекают не только одновременные, но и последовательные сравнения ценности
Вот «одновременная» модель принятия решений, описанная в книге «Голодный Мозг» Стефана Гийанэя на примере изучения миног:
Каждый участок паллиума [=эквивалент коры у миноги] связан с определенной частью полосатого тела. Паллиум посылает сигнал в полосатое тело, и затем сигнал из полосатого тела (через другие части базальных ганглиев) возвращается назад в тот же участок паллиума.
Иными словами, определенный участок паллиума и полосатое тело связаны замкнутой цепью, которая реализует запрос на конкретное действие. Например, существует цепь для преследования добычи, для ускользания от хищника, для прикрепления к камню и так далее. Каждый отдельный участок паллиума без конца нашептывает полосатому телу, упрашивая дать добро на исполнение того или иного поведенческого шаблона. А полосатое тело по умолчанию отвечает на это «нет!» При особых обстоятельствах шепот паллиума превращается в крик, и тогда полосатое тело исполняет требования настойчивого паллиума и приводит в действие мышцы.
Я принимаю это как часть моей модели принятия решений, но только как часть. Конкретнее, это одна из вещей, происходящих, когда Генератор Мыслей генерирует мысль. В самом деле, моя диаграмма в Разделе 6.3.4 выше явно вдохновлена этой моделью. Сравниваются разные одновременные возможности.
Другая часть моей модели – сравнение последовательных мыслей. Вы думаете одну мысль, а потом другую мысль (возможно, что сильно отличающуюся, а возможно, что преобразованную первую), и они сравниваются (Направляющей Подсистемой, отбирающей значение эмпирической истины, основываясь на, например, закономерностях того, как активизируются и успокаиваются Оценщики Мыслей), и если вторая хуже, то она ослабляется, чтобы её могла заменить следующая (возможно, снова первая).
Я могу процитировать эксперименты об аспекте последовательного сравнения в принятии решений (например, Рисунок 5 этой статьи, заявляющий то же, что и я), но действительно ли это надо? Интроспективно это очевидно! Вы думаете: «Хмм, думаю, я пойду в спортзал. На самом деле, что если я вместо этого пойду в кафе?» Вы представляете одно, а потом другое.
И я не думаю, что это то, что отличает людей от миног. Предполагаю, что сравнение последовательных мыслей универсально для позвоночных. Как иллюстрация того, что я имею в виду:
6.5.1 Выдуманный пример того, как сравнение последовательных мыслей могло бы выглядеть у более простого животного
Представьте простую древнюю маленькую рыбку, плывущую к пещере, где она живёт Она натыкается на развилку дороги, эмммм, «развилку в лесу водорослей»? Её текущий план навигации включает плыть налево к пещере, но у неё также есть вариант повернуть направо, чтобы добраться до рифа, где она часто кормится.
Я утверждаю, что её алгоритм навигации, увидев путь направо, рефлексивно загружает план: «Я поверну направо и доберусь до рифа.» Этот план немедленно оценивается и сравнивается с старым планом. Если новый план кажется хуже старого, то новая мысль затыкается, а старая мысль («Я направляюсь к своей пещере») восстанавливает своё положение. Рыбка без промедления продолжает следовать к пещере. А вот есть новый план кажется лучше старого, то новый план усиливается, приживается и принимает управление моторными командами. И тогда рыбка поворачивает направо и направляется к рифу.
(На самом деле, я не знаю достаточно о маленьких древних рыбках, но благодаря измерениям нейронов гиппокампуса известно, что крысы на развилке дороги лабиринта представляют оба возможных навигационных плана последовательно – ссылка.)
6.5.2 Сравнение последовательных мыслей: почему это необходимо
Согласно моим взглядам, мысли сложны. Чтобы подумать «Я пойду в кафе» вы не просто активируете некоторый крохотный кластер нейронов походов-в-кафе. Нет, это распределённый паттерн, включающий практически все части коры. Вы не можете одновременно думать «Я пойду в кафе» и «Я пойду в спортзал», потому что в эти мысли будут вовлечены разные паттерны активности одного и того же набора нейронов. Они бы мешали друг другу. Так что единственная возможность – думать мысли по очереди.
Как конкретный пример того, что я себе представляю, подумайте о том, как сеть Хопфилда не может вспомнить двенадцать воспоминаний одновременно. У неё есть множество стабильных состояний, но вы можете вызывать их только последовательно, одно за другим. Или подумайте о нейронах решётки и места, и т.д.
6.5.3 Сравнение последовательных мыслей: как это могло эволюционировать
Я представляю, что с эволюционной точки зрения сравнение последовательных мыслей – далёкий потомок очень простых механизмов сродни механизма «бежать-и-кувыркаться» у плавающих бактерий.
Механизм «бежать-и-кувыркаться» работает так: бактерия плывёт по прямой линии («бежит»), и периодически меняет направление на новое случайное («кувыркается»). Фокус в том, что, когда ситуация / окружение бактерии становится лучше, она кувыркается реже, а когда окружение становится хуже – она кувыркается чаще. Таким образом, она в итоге (в среднем, со временем) двигается в хорошем направлении.

Можно представить, как начиная с простого механизма вроде этого, можно навешивать на него всё больше и больше прибамбасов. Палитра поведенческих вариантов становится всё сложнее и сложнее, в какой-то момент превращаясь в «каждая мысль, которую возможно подумать». Методы оценивания, хорош или плох нынешний план, могут становиться быстрее и точнее, в итоге приводя к основанным на обучающихся алгоритмах предсказателям, как в предыдущем посте. Новые поведенческие варианты могут начать выбираться не случайно, а с помощью умных обучающихся алгоритмов. Так что мне кажется, что от чего-то-вроде-беги-и-кувыркайся к замысловатым тонко настроенным системам человеческого мозга, о которых я тут говорю есть плавный путь. (Иные размышления о бежать-и-кувыркаться и человеческой мотивации: 1, 2.)
6.6 Частые заблуждения
6.6.1 Различие между интернализированными эгосинтоническими и экстернализированными эгодистоническими желан иями не связано с разделением на Обучающуюся Подсистему и Направляющую Подсистему
(См. также: мой пост (Мозговой ствол, Неокортекс) ≠ (Базовые мотивации, Благородные мотивации).)
Многие (включая меня) обладают сильным интуитивным разделением эгосинтонических стремлений, которые являются «частью нас» и «тем, чего мы хотим» от эгодистонических стремлений, ощущающихся как позывы, вторгающиеся в нас извне.
К примеру, гурман может сказать: «Я люблю хороший шоколад», а человек на диете – «Я чувствую позыв съесть хороший шоколад».
6.6.1.1 Объяснение, которое мне нравится
Я утверждаю, что эти два человека по сути описывают одно и то же ощущение, с по сути одинаковой нейроанатомической локализацией и по сути одинаковой связью с низкоуровневыми алгоритмами мозга. Но гурман признаёт это чувство, а человек на диете его экстернализирует.
Эти два разных концепта идут рука об руку с двумя разными «предпочтениями высшего уровня»: гурман хочет хотеть есть хороший шоколад, тогда как человек на диете хочет не хотеть есть хороший шоколад.
Это приводит нас к прямолинейному психологическому объяснению, почему гурман и человек на диете по-разному концептуализируют свои чувства:
- Гурману приятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Так он и делает.
- Человеку на диете неприятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Поэтому он так не делает.
6.6.1.2 Объяснение, которое мне не нравится
Многие (включая Джеффа Хокинса, см. Пост №3) замечают описанное выше различие и, отдельно, поддерживают (как и я) идею, что в мозгу есть Обучающаяся Подсистема и Направляющая Подсистема (опять же, см. Пост №3). Они естественно предполагают, что это эквивалентно тому, что «я и мои глубокие желания» соответствуют Обучающейся Подсистеме, а «позывы, с которыми я себя не идентифицирую» – Направляющей Подсистеме.

Я думаю, что эта модель неверна. По меньшей мере, если вы хотите принимать эту модель, то вам придётся отвергнуть приблизительно всё, что я писал в этом и предыдущих четырёх постах.
В моей модели, если вы пытаетесь воздержаться от шоколада, но чувствуете позыв есть шоколад, то:
- У вас есть позыв есть шоколад, потому что Направляющая Подсистема одобряет мысль «я сейчас съем шоколад»; И
- Вы пытаетесь воздержаться от шоколада, потому что Направляющая Подсистема одобряет мысль «Я воздерживаюсь от шоколада».
(С чего Направляющей Подсистеме одобрять вторую мысль? Это зависит от человека, но готов поспорить, что в это вовлечены социальные инстинкты. Я больше поговорю про социальные инстинкты в Посте №13. Если вы ходите менее сложный пример, представьте человека с непереносимостью лактозы, пытающегося сопротивляться позыву прямо сейчас съесть вкусное мороженое, потому что это приведёт к очень плохим ощущениям потом. Направляющей Подсистеме нравятся планы, не приводящие к болезненным ощущениям, но ей также нравятся планы, приводящие к поеданию вкусного мороженого.)
6.6.2 Обучающаяся Подсистема и Направляющая Подсистема – не два агента
Другая частая ошибка – воспринимать саму по себе Обучающуюся или Направляющую Подсистему как что-то вроде независимого агента. Это неверно с обеих сторон:
- Обучающаяся Подсистема не может думать никаких мыслей, если Направляющая Подсистема не одобрила их как стоящие думания.
- В то же время, Направляющая Подсистема сама по себе не понимает мир или себя. У неё нет явных целей на будущее. Она лишь относительно простая, жёстко закодированная машина ввода-вывода.
Как пример, совершенно возможно следующее:
- Обучающаяся Подсистема генерирует мысль «Я собираюсь хирургически изменить мою Направляющую Подсистему».
- Оценщики Мыслей сводят эту мысль к «оценочной таблице».
- Направляющая Подсистема получает оценочную таблицу и исполняет свои жёстко прошитые эвристики, и результат: «Очень хорошая мысль, давай сделаем это!»
Почему нет, верно? Я больше поговорю про этот пример в позднейших постах.
Если вы прочитали пример выше и подумали: «Ага! Это случай, когда Обучающаяся Подсистема обхитрила Направляющую Подсистему», то вы всё ещё не поняли.
(Может, попробуйте представить Обучающуюся и Направляющую Подсистемы как две сцепленных шестерни в одном механизме.)
***
- Как и в предыдущем посте, термин «эмпирическая истина» тут немного обманчив, потому что иногда Направляющая Подсистема просто доверяется Оценщикам Мыслей.
- Как и в предыдущем посте, я не считаю, что на самом деле есть чистая дихотомия между режимом «довериться предсказателю» и «перехватить». На самом деле, я готов поспорить, что Направляющая Подсистема может частично-но-не-совсем-полностью довериться Оценщику Мыслей, например, взяв взвешенное среднее от Оценщика Мыслей и какого-то другого независимого вычисления.
